Что такое мониторинг ИТ-инфраструктуры и зачем он бизнесу
Мониторинг ИТ-инфраструктуры — это системный процесс сбора, анализа и визуализации информации о состоянии и производительности всех компонентов информационной среды компании: от серверного оборудования и сетевых устройств до приложений, баз данных и пользовательского интерфейса.
Цель мониторинга — обеспечить полную наблюдаемость за ИТ‑системами, своевременно выявлять аномалии и отклонения от нормального поведения, быстро реагировать на сбои и инциденты, а также принимать обоснованные управленческие решения на основе объективных данных.
На базовом уровне мониторинг решает задачи технической эксплуатации: отслеживает нагрузку на серверы, потребление памяти, сетевой трафик, доступность сервисов и т. д. Однако для бизнеса он выполняет гораздо более значимые функции:
Снижение времени простоя (downtime)
Неполадки в ИТ-системах напрямую влияют на работу бизнес-приложений, особенно в сферах с высоким уровнем цифровизации, таких как онлайн-банкинг, e-commerce, логистика. Эффективный мониторинг позволяет оперативно обнаруживать и устранять сбои, тем самым минимизируя ущерб.
Обеспечение соблюдения SLA и повышение качества обслуживания
Договорные обязательства перед внутренними и внешними заказчиками предполагают определенный уровень доступности и стабильности сервисов. Мониторинг позволяет отслеживать выполнение SLA в реальном времени и немедленно реагировать на их нарушение.
Поддержка принятия управленческих решений
Анализ исторических данных мониторинга помогает оценивать эффективность ИТ-ресурсов, выявлять узкие места, прогнозировать нагрузку и принимать обоснованные решения по масштабированию, миграции в облако или замене устаревших компонентов.
Устойчивость к инцидентам и киберугрозам
Мониторинг ИТ-инфраструктуры является важной частью комплексной стратегии обеспечения кибербезопасности. Он позволяет выявлять аномальное поведение систем, возможные признаки атак или несанкционированного доступа задолго до наступления критических последствий.
Фундамент для автоматизации и внедрения DevOps/AIOps-практик
Современный ИТ-мониторинг не только собирает данные, но и позволяет интегрировать их в процессы CI/CD, сервис-деск и управление инцидентами. Это делает возможным построение высокоавтоматизированной среды и снижение человеческого фактора.
От частичного к предиктивному мониторингу ИТ-инфрастуктуры на базе искусственного интеллекта
На практике компании редко начинают цифровую трансформацию с внедрения централизованной системы мониторинга. Чаще всего все начинается с точечных решений: отдельно мониторится сеть, отдельно — серверы, в лучшем случае — прикладной уровень. Такой подход дает краткосрочный эффект, но быстро перестает соответствовать масштабу, скорости изменений и сложности современной ИТ-инфраструктуры.
Переход к зрелой, проактивной модели наблюдаемости — это путь, состоящий из нескольких этапов. Каждый следующий этап строится на результатах предыдущего, но требует переосмысления подходов, инструментов и организационных процессов. Ниже рассмотрим, как выглядит эта эволюция — от фрагментарного контроля к интеллектуальному управлению ИТ-сервисами.
Частичный мониторинг
Одним из первых шагов на пути к построению системы мониторинга ИТ-инфраструктуры обычно становится точечное внедрение инструментов в те сегменты, где сбои возникают чаще всего. Такой подход позволяет частично сократить время простоя бизнес-критичных приложений и сервисов за счет оперативной фиксации инцидентов в контролируемой зоне.
Однако на практике он сопровождается рядом ограничений. В разных частях ИТ-ландшафта используются разные инструменты мониторинга, между которыми отсутствует централизованная координация. Это затрудняет формирование единой картины состояния инфраструктуры и особенно понимание влияния отдельных компонентов (серверов, СУБД, систем виртуализации, сетевого оборудования) на конечные бизнес-сервисы.
В результате нарушается приоритезация: все инциденты обрабатываются условно последовательно, без учета их реального воздействия на непрерывность бизнес-процессов. Те проблемы, которые не влияют на критичные приложения, могут отвлекать ресурсы и замедлять реакцию на действительно значимые сбои.
Кроме того, при частичном покрытии мониторингом основное время восстановления сервиса (TTR) уходит не столько на устранение, сколько на обнаружение самой проблемы. Отсутствие полноты наблюдаемости приводит к затяжным расследованиям причин, что снижает общую эффективность ИТ-поддержки и увеличивает бизнес-риски.
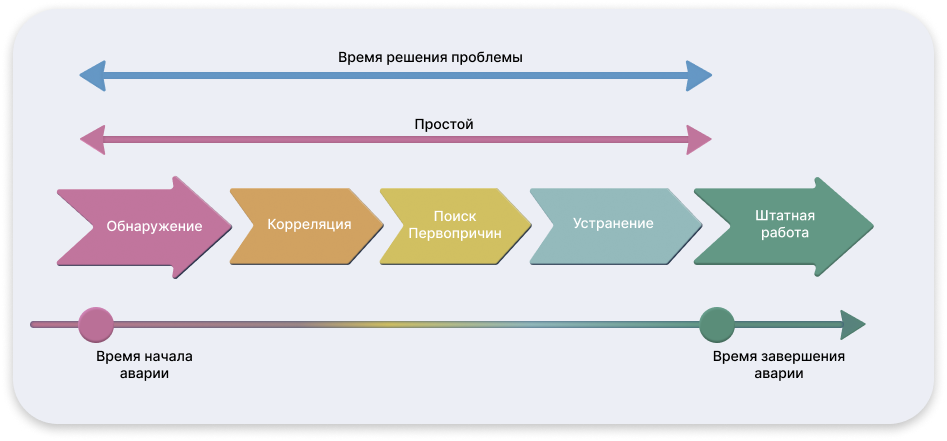
Сквозной мониторинг с элементами проактивности
Следующим уровнем зрелости мониторинга является внедрение сквозного мониторинга всех элементов ИТ-ландшафта. Он охватывает не только базовую инфраструктуру, но и компоненты приложений, пользовательский опыт и сетевую связность.
Речь идет о наблюдаемости на всех уровнях:
Мы в Telegram
Подпишитесь на Telegram-канал wiSLA и оставайтесь в курсе последних новостей!
Подписаться
-
Пользовательский уровень — имитация действий реального пользователя или интеграционного сервиса;
-
Прикладной уровень — активные процессы, сервер приложений, внутренние логи;
-
Инфраструктурный уровень — серверы, виртуальные машины, СУБД, средства виртуализации;
-
Сетевой уровень — каналы связи, сетевое оборудование, точки обмена данными.
Для построения такой системы, как правило, используется единый инструмент или комплекс решений, обеспечивающих централизованный сбор данных. Это может быть либо внедрение «зонтичной» платформы, которая агрегирует данные из различных источников, либо унификация инструментов в разных сегментах. Нередко применяется комбинированный подход, включающий оба варианта.
Ключевым преимуществом сквозного мониторинга является возможность корреляции событий между различными слоями ИТ-среды. Это позволяет понять, как сбой на одном уровне (например, в виртуализации) влияет на другие уровни — приложения, БД, пользовательский опыт. На практике такие взаимосвязи выявляются с помощью ручной корреляции на основе сопоставления инцидентов, зафиксированных в одно и то же время.
Однако данный подход имеет и свои ограничения. Основная проблема — высокий объем событий, поступающих в мониторинговую систему. Не все из них оказывают реальное влияние на работу бизнес-критичных сервисов, но создают информационный шум, затрудняющий ручную обработку и повышающий нагрузку на ИТ-команду. Это снижает эффективность анализа и увеличивает риск пропуска действительно значимых инцидентов.
Тем не менее, внедрение сквозного мониторинга с возможностью корреляции событий дает значительный эффект. Он позволяет полностью исключить задержки, связанные с обнаружением инцидентов, а также существенно сократить время на их диагностику. В результате снижается общее время восстановления (MTTR), повышается устойчивость бизнес-критичных приложений и формируется основа для перехода к проактивной модели управления.
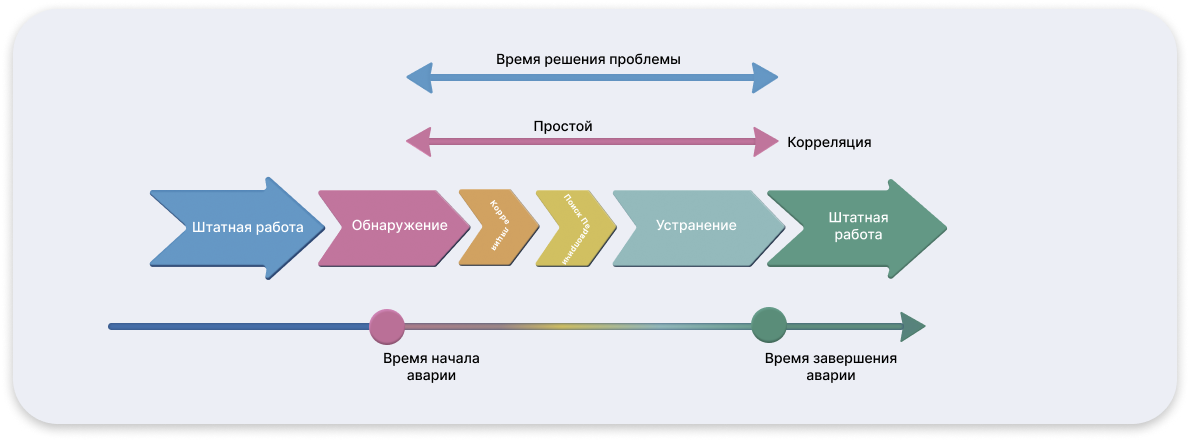
Проактивный мониторинг с ML-корреляцией
Одним из наиболее передовых подходов к обеспечению непрерывности работы бизнес-критичных приложений сегодня считается переход от проактивного мониторинга к предиктивной модели. В основе этого перехода лежит внедрение экспертных аналитических подсистем, использующих машинное обучение и интеллектуальную корреляцию событий. Их задача не просто фиксировать инциденты в момент их возникновения, а предсказывать их с высокой степенью вероятности на основе поведенческих аномалий в системе.
Такие подсистемы подключаются к сквозному мониторингу и получают из него данные в реальном времени. Помимо этого, в качестве источников информации используются логи приложений, системные журналы, трассировки и другие виды телеметрии. Объединяя информацию из различных каналов, аналитическая система формирует полную картину происходящего в инфраструктуре.
На следующем этапе происходит кластеризация и дедупликация событий: группировка повторяющихся или взаимосвязанных сигналов в единые логические блоки. Затем система с помощью алгоритмов машинного обучения строит шаблоны поведения и графы связей между событиями, анализируя вероятностные зависимости и характерные последовательности, предшествующие сбоям. На основе этих шаблонов осуществляется детекция аномалий — ситуаций, отклоняющихся от нормального функционирования и совпадающих по структуре с историей предыдущих инцидентов.
Если система фиксирует аномалию, связанная с ней совокупность факторов анализируется на предмет риска дальнейшей эскалации. Таким образом формируется прогностическая модель, оценивающая вероятность того, что зафиксированное отклонение перерастает в проблему, затрагивающую работу бизнес-сервиса.
Применение такого подхода позволяет выявлять потенциальные угрозы ещё до того, как они станут заметны пользователям или приведут к сбою. ИТ-команды получают возможность начать корректирующие действия заблаговременно — в ряде случаев предотвращая инцидент полностью, в других — существенно сокращая его последствия и длительность простоя.
Благодаря интеграции ML-корреляции в архитектуру мониторинга, система превращается из инструмента контроля в интеллектуального помощника, способного оценивать контекст, приоритеты и степень риска. Это не только снижает операционную нагрузку, но и качественно повышает уровень зрелости цифровой среды.
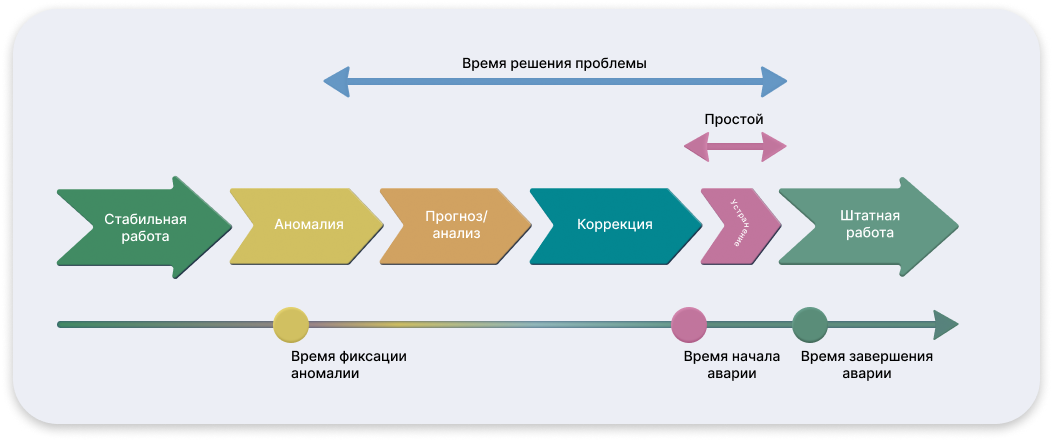
Обеспечение и эксплуатация системы мониторинга
Даже самые современные решения в области мониторинга и ML-корреляции остаются всего лишь инструментами. Эффективными, гибкими и функциональными, но не самодостаточными. Для того чтобы система действительно работала в интересах бизнеса, ее необходимо не только правильно внедрить, но и научиться ею пользоваться, выстроив процессы эксплуатации и поддержки.
На практике после технического развертывания организации сталкиваются с рядом вопросов:
-
Как объединить набор показателей разного уровня критичности в агрегированную модель?
-
В чьей зоне ответственности находится та или иная ошибка/авария?
-
Как сократить информационный шум в событиях?
-
И самое главное: как сократить время простоя еще больше?
Одним из наиболее эффективных подходов к решению этих задач является создание Единого центра аналитики и мониторинга. Это не просто техническая платформа, а комплекс организационно-технических мер, направленных на обеспечение устойчивой работы систем наблюдаемости, корректную интерпретацию данных, контроль выполнения SLA, а также распределение ответственности между подразделениями и внешними подрядчиками.
Функционал такого центра охватывает три ключевых направления: техническое, организационное и аналитическое.
С технической точки зрения центр обеспечивает постановку на мониторинг сложных объектов, верификацию результатов автообнаружения (AutoDiscovery), контроль непрерывности сбора данных и регламентное обслуживание систем мониторинга.
В организационном аспекте центр отвечает за аудит критичных ИТ-ресурсов, разработку и согласование методологии мониторинга, унификацию отчётности и координацию процессов реагирования между различными подразделениями.
Особую роль играет аналитическое направление, в фокусе которого находится использование механизмов ML-корреляции. Здесь решаются задачи по агрегации показателей в комплексную модель «здоровья» сервисов, верификации автоматически сформированных шаблонов корреляции, а также построению и анализу графов связей между событиями и объектами ИТ-инфраструктуры.
В результате такая модель централизованного управления позволяет достичь главной цели: обеспечить прозрачное понимание причинно-следственных связей в инфраструктуре, предсказывать потенциальные инциденты на основе выявленных аномалий и предпринимать превентивные меры до наступления сбоя. Это позволяет не просто реагировать быстрее, а существенно сократить время простоя критичных компонентов ИТ и повысить общую устойчивость цифровой среды компании.
Заключение
Надежный, интеллектуальный и масштабируемый мониторинг ИТ-инфраструктуры — это ключевой элемент обеспечения устойчивости и непрерывности цифрового бизнеса. В условиях высокой сложности ИТ-ландшафтов, множественных зависимостей и критически высоких требований к доступности сервисов компании больше не могут полагаться на фрагментарные инструменты или ручное реагирование.
Переход от частичного мониторинга к сквозной модели наблюдаемости, дополненной ML-корреляцией и предиктивной аналитикой, позволяет принципиально изменить подход к управлению ИТ-сервисами. От фиксирования последствий — к прогнозированию причин. От избыточного шума — к приоритизированной и точной информации. От постфактум-реакции — к заблаговременным корректирующим действиям.
При этом инструментальная платформа — лишь одна часть уравнения. Чтобы получить реальную бизнес-ценность, необходимо выстроить устойчивые процессы эксплуатации, создать единый центр аналитики и мониторинга, обеспечить методологическую и организационную целостность. Только тогда система наблюдаемости становится действительно управляющим механизмом, а не просто техническим решением.
Интеллектуальный мониторинг — это шаг к зрелой, предсказуемой и управляемой ИТ-инфраструктуре, где каждый инцидент рассматривается не как неожиданность, а как сценарий, которому можно и нужно заблаговременно противодействовать.
