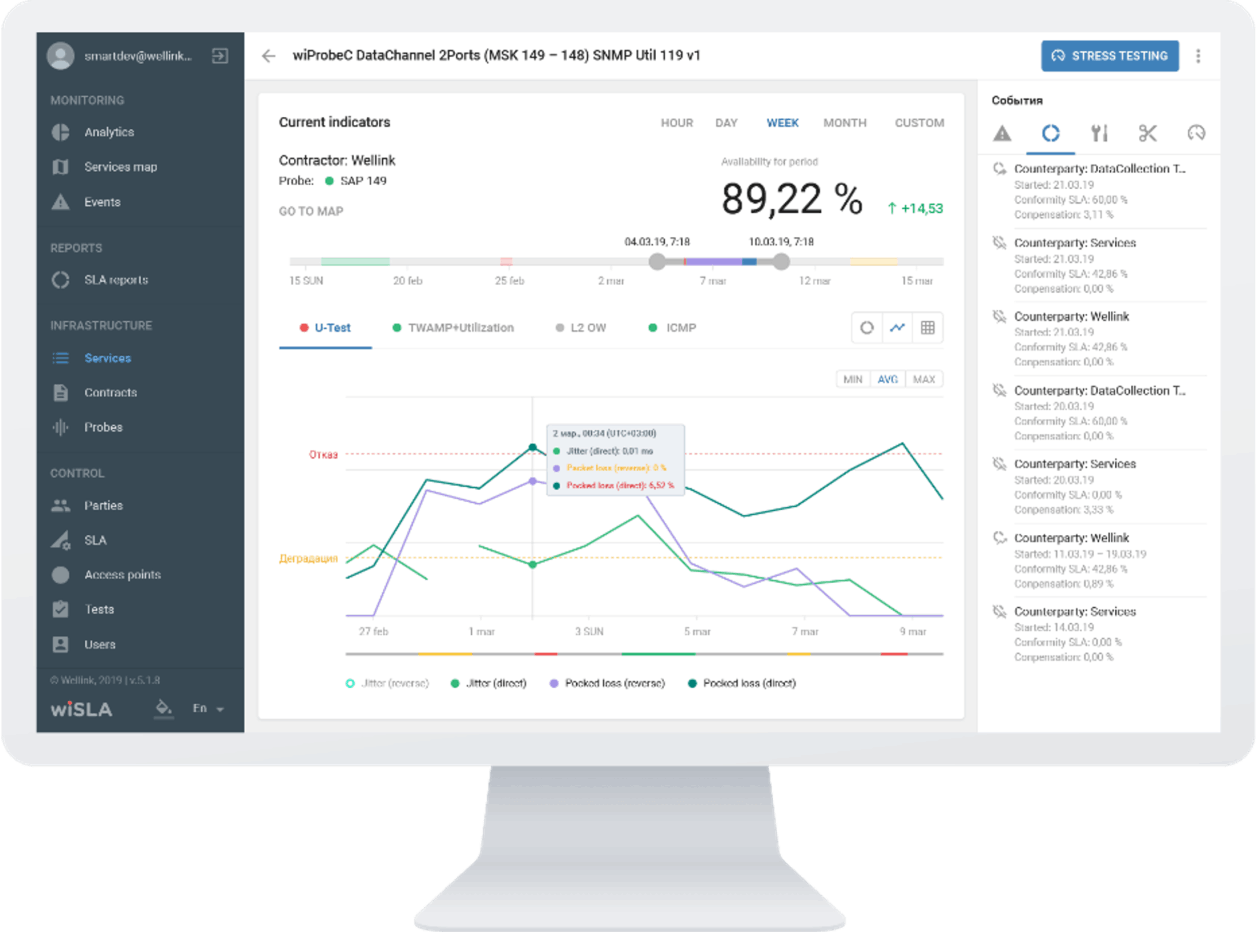
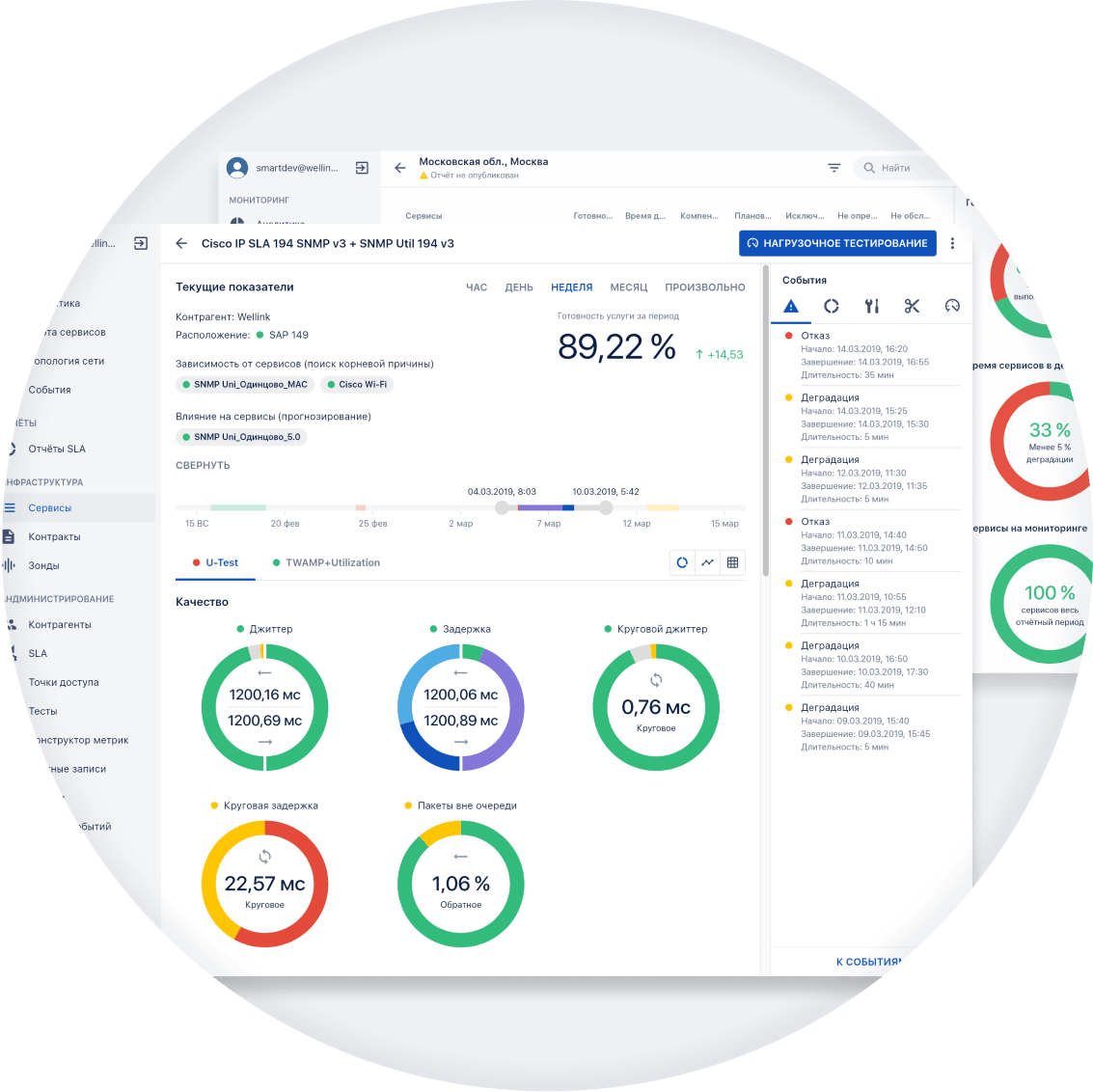
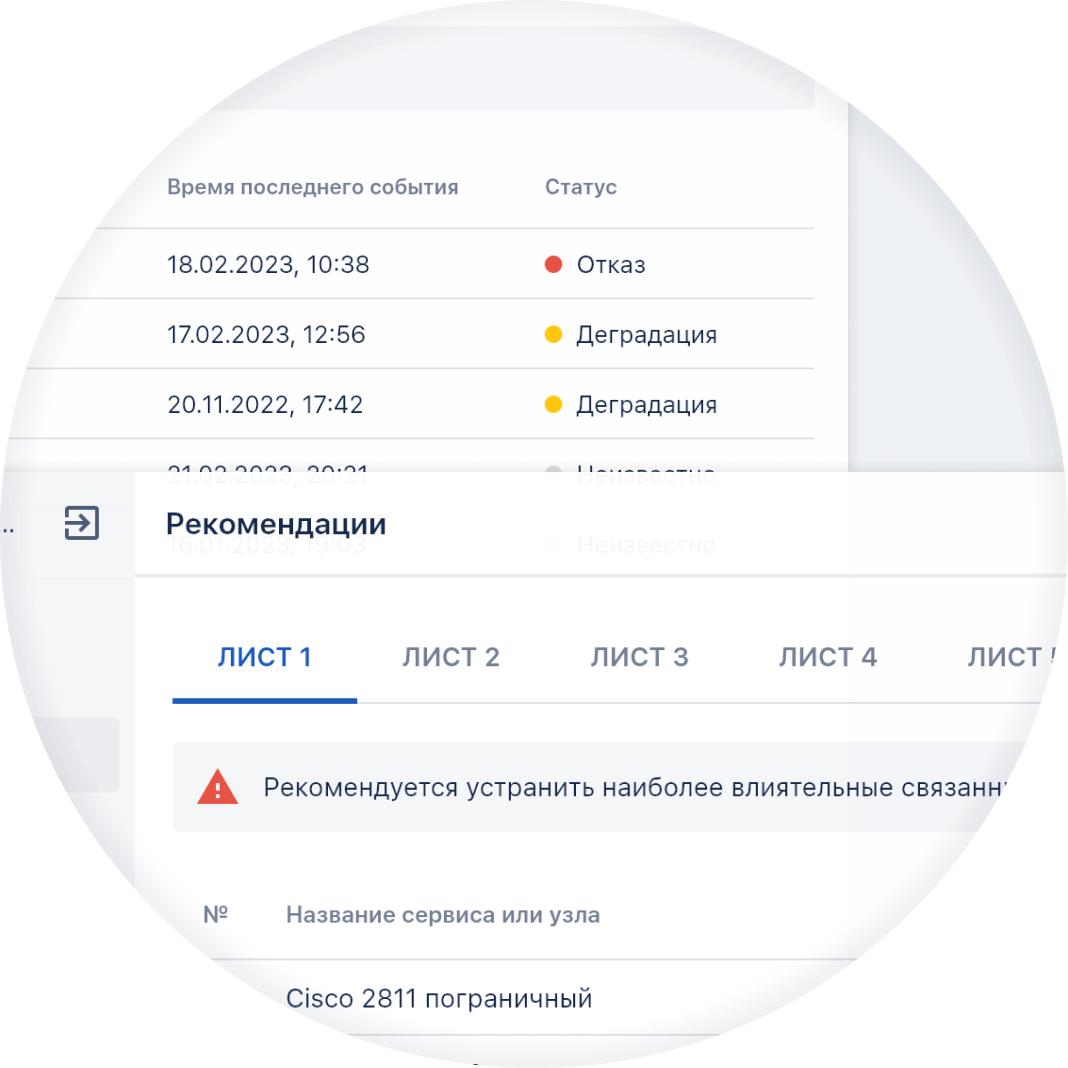
wiSLA использует ИИ и машинное обучение для реализации функциональности AIOps в части:
Расчет корреляции событий
Построение карты причинно-следственных связей аномальных событий с
оценкой их вероятностей, взаимного влияния и комплексного параметра
влияния (весов).
Обработка больших объемов данных и уменьшение информационного шума
Формирование целостной картины инцидента: агрегирование и дедупликация
событий, анализ причинно-следственных связей и выделение цепочек
взаимосвязанных событий, которые привели к сбою.
Прогнозная аналитика и обнаружение инцидентов на ранней стадии
Автоматическая оценка и прогнозирование влияния проблем на критичные
узлы и сервисы. Расчет вероятного развития и предсказание возможных
последствий инцидентов на ранних этапах жизненного цикла.
Автоматический поиск первопричин (Root Cause Analysis)
Автоматическое построение связей между данными из любой точки
технологических стеков, определение наиболее вероятных коренных причин
проблем, ухудшающую качество обслуживания клиентов.
Комплексный анализ системы и выявление узких мест
Формирование ранжированного списка аномалий по степени влияния с
указанием наиболее критичных компонентов и ИТ-сервисов, а также
возможность ретроспективного анализа аномалий и их взаимосвязей.
Выдача рекомендаций по оптимизации и стабилизации системы
Использование выявленных закономерностей и анализа цепочек аномальных
событий для непрерывной оптимизации ИТ-инфраструктуры, повышения
надежности систем, эффективности ИТ-операций и проактивного
предотвращения инцидентов.
Единый интуитивный интерфейс управления ИТ-инцидентами
ИИ-функционал интегрирован на всех уровнях wiSLA: от агрегирования и
фильтрации событий до расследования инцидентов, прогнозирования
последствий, поиска узких мест и формирования рекомендаций — все в
едином интерфейсе для быстрого реагирования и принятия решений в режиме
реального времени.
